C++ STL
STL介绍
STL(Standard Template Library),即标准模板库,是一个具有工业强度的,高效的C++程序库。它被容纳于C++标准程序库(C++ Standard Library)中,是ANSI/ISO C++标准中最新的也是极具革命性的一部分。该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。
从逻辑层次来看,在STL中体现了泛型化程序设计的思想(generic programming),引入了诸多新的名词,比如像需求(requirements),概念(concept),模型(model),容器(container),算法(algorithmn),迭代子(iterator)等。与OOP(object-oriented programming)中的多态(polymorphism)一样,泛型也是一种软件的复用技术;
从实现层次看,整个STL是以一种类型参数化(type parameterized)的方式实现的,这种方式基于一个在早先C++标准中没有出现的语言特性–模板(template)。如果查阅任何一个版本的STL源代码,你就会发现,模板作为构成整个STL的基石是一件千真万确的事情。除此之外,还有许多C++的新特性为STL的实现提供了方便;
STL的六大组件
1.容器(Container),是一种数据结构,如list,vector,和deques ,以模板类的方法提供。为了访问容器中的数据,可以使用由容器类输出的迭代器;
2.迭代器(Iterator),提供了访问容器中对象的方法。例如,可以使用一对迭代器指定list或vector中的一定范围的对象。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。但是,迭代器也可以是那些定义了operator*()以及其他类似于指针的操作符地方法的类对象;
3.算法(Algorithm),是用来操作容器中的数据的模板函数。例如,STL用sort()来对一个vector中的数据进行排序,用find()来搜索一个list中的对象,函数本身与他们操作的数据的结构和类型无关,因此他们可以在从简单数组到高度复杂容器的任何数据结构上使用;
3.仿函数(Function object,仿函数(functor)又称之为函数对象(function object),其实就是重载了()操作符的struct,没有什么特别的地方;
4.迭代适配器(Adaptor)
5.空间配制器(allocator)*其中主要工作包括两部分:
1.对象的创建与销毁;
2.内存的获取与释放;
STL-vector
vector向量相当于一个数组,在内存中分配一块连续的内存空间进行存储。使用vector记得包含:
#include <vector>
vector的初始化和销毁
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector<int> vec1; //用push_back初始化
vec1.push_back(1);
vec1.push_back(2);
vec1.push_back(3);
int arr1[10]={1,2,3,4,5,6,7,8,9,10}; //用数组初始化
vector<int> vec2(arr1,arr1+10);
vector<int> vec3(5,1); //大小为5 初始化初值为1
vector<int> vec4(4,0);
vec4.~vector<int>(); //销毁所有数据,释放资源
return 0;
}

vector常用的函数
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector<int> vec1; //在容器最后位置添加一个元素
vec1.push_back(1);
vec1.push_back(2);
vec1.push_back(3);
vec1.push_back(3);
vec1.pop_back(); //删除容器最后位置处的元素
//vec.begin();返回指向容器最开始位置数据的指针
//vec.end(); 返回指向容器最后一个数据单元的指针+1
cout<<vec1.end()-vec1.begin()<<endl; //3
//vec1.front(); 返回容器最开始单元数据的引用
//vec1.back(); 返回容器最后一个数据的引用
cout<<vec1.front()<<" "<<vec1.back()<<endl; //1 3
//vec1.size(); 返回当前容器中实际存放元素的个数
cout<<vec1.size()<<endl; //3
//声明一个迭代器
vector<int>::iterator it;
//vec1.erase(p); 删除指针p指向位置的数据 返回下指向下一个数据位置的指针(迭代器)
//vec1.erase(begin,end) 删除begin,end区间的数据 返回指向下一个数据位置的指针(迭代器)
it=vec1.begin();
vec1.erase(it+1);
//vec1.empty(); 判断容器是否为空 若为空返回true 否则返回false
cout<<vec1.empty()<<endl; //0
//vec1.swap(vec2); 交换两个容器中的数据
//vec1.insert(p,elem); 在指针p指向的位置插入数据elem 返回指向elem位置的指针
//vec1.insert(p,n,elem); 在位置p插入n个elem数据 无返回值
//vec1.insert(p,begin,end) 在位置p插入在区间[begin,end)的数据 无返回值
vec1.insert(it+1,10);
//vector支持数组下标访问方式
cout<<vec1[1]<<endl;
system("pause");
}
vector排序sort
必须包含头文件:
#include <algorithm>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool cmpDec(int a,int b){ //降序排列
return a>b;
}
int main(){
int arr1[10]={9,3,5,2,8,5,4,12,11,1};
vector<int> vec1(arr1,arr1+10);
vector<int> vec2(vec1);
sort(vec2.begin(),vec2.end()); //sort默认是升序排列
vector<int> vec3(vec1);
sort(vec3.begin(),vec3.end(),cmpDec); //自定义排序函数实现降序排列
system("pause");
}
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//先自定义一个结构体
struct Test{
int member1;
int member2;
};
void MyPushback(vector<Test> &vecTest,int m1,int m2){
Test test;
test.member1 = m1;
test.member2 = m2;
vecTest.push_back(test);
}
bool cmp1(const Test &a,const Test &b){
return a.member1<b.member1; //以第一个成员进行升序排序
}
bool cmp2(const Test &a,const Test &b){
return a.member2<b.member2; //以第二个成员进行升序排序
}
void PrintVector(vector<Test> &vec){ //打印向量
int s=vec.size();
for(int i=0;i<s;i++){
cout<<vec[i].member1<<" "<<vec[i].member2<<endl;
}
}
int main(){
vector<Test> vecTest;
MyPushback(vecTest,9,1);
MyPushback(vecTest,8,2);
MyPushback(vecTest,7,3);
MyPushback(vecTest,6,4);
MyPushback(vecTest,5,5);
MyPushback(vecTest,4,6);
MyPushback(vecTest,3,7);
MyPushback(vecTest,2,8);
MyPushback(vecTest,1,9);
cout<<"原始数据:"<<endl;
PrintVector(vecTest);
vector<Test> vecTest1(vecTest);
sort(vecTest1.begin(),vecTest1.end(),cmp1);
cout<<"以第一个成员进行升序排序:"<<endl;
PrintVector(vecTest1);
vector<Test> vecTest2(vecTest);
sort(vecTest2.begin(),vecTest2.end(),cmp2);
cout<<"以第二个成员进行升序排序:"<<endl;
PrintVector(vecTest2);
system("pause");
}

//不自定义排序函数,使用C++ STL强大功能实现排序规则,
//从小到大排序,比较函数设置为:less<数据类型>
//从大到小排序,比较函数设置为:greater<数据类型>
#include <iostream>
#include <algorithm>
#include <vector> //好像一定要包含vector或者list 否则greater或者less无法使用
using namespace std;
int main()
{
int a[10]={9,6,3,8,5,2,7,4,1,0};
for(int i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
sort(a,a+10,less<int>()); //从大到小排序,从小到大则为less<int>
for(int i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
system("pause");
}
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void printvec(vector<int> &vec){
int len=vec.size();
for(int i=0;i<len;i++){
cout<<vec[i]<<" ";
}
cout<<endl;
}
int main()
{
int a[10]={3,6,9,2,5,8,1,4,7,0};
vector<int> vec(a,a+10);
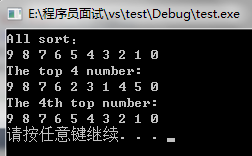
cout<<"All sort:"<<endl;
vector<int> vec1(vec);
sort(vec1.begin(),vec1.end(),greater<int>());
printvec(vec1);
//partial_sort实现局部排序 例如寻找最大的前4个数
//相当于用sort把所有排好序 然后再取前4个
cout<<"The top 4 number: "<<endl;
vector<int> vec2(vec);
partial_sort(vec2.begin(),vec2.begin()+4,vec2.end(),greater<int>());
printvec(vec2);
//nth_element实现取第几大的数据
cout<<"The 4th top number: "<<endl;
vector<int> vec3(vec);
nth_element(vec3.begin(),vec3.begin()+3,vec3.end(),greater<int>());
printvec(vec3);
system("pause");
}
vector求最大值、最大值索引和最小值、最小索引
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
int a[10]={3,6,9,2,5,8,1,4,7,0};
vector<int> vec(a,a+10);
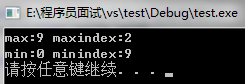
int max=*max_element(vec.begin(),vec.end()); //最大值
int maxindex=max_element(vec.begin(),vec.end())-vec.begin(); //最大值索引
cout<<"max:"<<max<<" "<<"maxindex:"<<maxindex<<endl;
int min=*min_element(vec.begin(),vec.end()); //最小值
int minindex=min_element(vec.begin(),vec.end())-vec.begin(); //最小值索引
cout<<"min:"<<min<<" "<<"minindex:"<<minindex<<endl;
system("pause");
}
vector中find函数
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
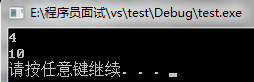
int a[10]={3,6,9,2,5,8,1,4,7,0};
vector<int> vec(a,a+10);
int index1=find(vec.begin(),vec.end(),5)-vec.begin();
cout<<index1<<endl;
int index2=find(vec.begin(),vec.end(),-1)-vec.begin();
cout<<index2<<endl;
system("pause");
}
vector的优缺点
vector是一种随机访问的数组类型(因此可以使用操作符[]或at()来进行访问),提供了对数组元素进行快速随机访问以及在序列尾部进行快速的插入和删除操作的功能,可以再需要的时候修改其自身的大小。
缺点:
(1) 在内部进行插入删除操作效率低。
(2) 只能在vector的最后进行push和pop,不能在vector的头进行push和pop。
(3) 当动态添加的数据超过vector默认分配的大小时要进行整体的重新分配、拷贝与释放。
vector是访问非常高效,但是在内部插入和删除就会很慢(连续的数据结构访问是很快的,但插入和删除是很慢的,因为插入删除以后需要移动位置)。
STL-list
STL中的list就是一双向链表,可高效地进行插入删除元素。list不支持随机访问。所以没有操作符[]和at()。
使用list容器之前必须加上头文件:
#include <list>;
list的初始化
list的初始化基本上和vector差不多。
list<int> g_list1;
list<int> g_list2;
//push_back()增加一元素到链表尾
g_list1.push_back(1);
g_list1.push_back(2);
g_list1.push_back(3);
//push_front()增加一元素到链表头
g_list2.push_front(6);
g_list2.push_front(5);
g_list2.push_front(4);
list<int> g_list3(5,1); //创建一个含五个元素的链表 值都是1
list<int> g_list4(g_list1); //拷贝创建
int arr[5]={1,2,3,4,5};
list<int> L(arr,arr+5);
返回第一个元素和最后一个元素
int nRet = list1.front()
int nRet = list1.back()
头和尾增加元素
list.push_front(4); //增加一元素到链表头
list.push_back(4); //增加一元素到链表尾
头和尾删除元素
list.pop_front(); //删除链表头的一元素
list.pop_back(); //删除链表尾的一个元素
reverse()反转链表
//原始list:list1(1,2,3)
list1.reverse(); //list1(3,2,1)
merge()合并两个有序链表并使之有序
//升序
原始list:list1(1,2,3) list2(4,5,6)
list1.merge(list2); //list1(1,2,3,4,5,6) list2现为空
// 降序
原始list:L1(3,2,1) L2(6,5,4)
L1.merge(L2, greater<int>()); //L1(6,5,4,3,2,1) L2现为空
注意:
1)merge()是将两个有序的链表合并成另一个有序的链表,如果有一个链表不是有序的那么在执行代码时会报错:说链表不是有序的。
2)还有,两个链表中的内容排序顺序与合并时采用的排序顺序必须一致,如果不一致,也会报错,说链表不是有序的。如想要降序合并两个链表,那么合并前的两个链表也必须是按降序排列的。
3)另外,当执行完merge()后,右边的链表将变为空。
insert()在指定位置插入一个或多个元素(三个重载函数)
原始list:list1(1,2,3) list2(4,5,6)
list1.insert(++list1.begin(),9); //list1(1,9,2,3)
list1.insert(list1.begin(),2,9); //list1(9,9,1,2,3);
list1.insert(list1.begin(),list2.begin(),--list2.end()); //list1(4,5,1,2,3);
erase()删除一个元素或一个区域的元素(两个重载函数)
//原始list:list1(1,2,3)
list1.erase(list1.begin()); //list1(2,3)
list1.erase(++list1.begin(),list1.end()); //list1(1)
swap()交换两个链表(两个重载)
原始list:list1(1,2,3) list2(4,5,6)
list1.swap(list2); //list(4,5,6) list2(1,2,3)
unique()删除相邻重复元素
原始list:L1(1,1,4,3,5,1)
L1.unique(); //L1(1,4,3,5,1)
empty()判断是否链表为空
bool bRet = L1.empty(); //若L1为空,bRet = true,否则bRet = false
assign()分配值(有两个重载)
L1.assign(4,3); //L1(3,3,3,3)
原始list:list1(1,2,3)
L1.assign(++list1.beging(), list2.end()); //L1(2,3)
list总结
list是一种序列式容器。list容器完成的功能实际上和数据结构中的双向链表是极其相似的,list中的数据元素是通过链表指针串连成逻辑意义上的线性表,也就是list也具有链表的主要优点,即:在链表的任一位置进行元素的插入、删除操作都是快速的。
list的实现大概是这样的:list的每个节点有三个域:前驱元素指针域、数据域和后继元素指针域。前驱元素指针域保存了前驱元素的首地址;数据域则是本节点的数据;后继元素指针域则保存了后继元素的首地址。其实,list和循环链表也有相似的地方,即:头节点的前驱元素指针域保存的是链表中尾元素的首地址,list的尾节点的后继元素指针域则保存了头节点的首地址,这样,list实际上就构成了一个双向循环链。
由于list元素节点并不要求在一段连续的内存中,显然在list中是不支持快速随机存取的,因此对于迭代器,只能通过“++”或“–”操作将迭代器移动到后继/前驱节点元素处。而不能对迭代器进行+n或-n的操作,这点,是与vector等不同的地方。
因此list就是插入和删除很高效,但访问就慢了(因为链表需要一个一个遍历访问)。
STL-deque
deque容器类与vector类似,支持随机访问(能使用操作符[]或者at())和快速插入删除,它在容器中某一位置上的操作所花费的是线性时间。与vector不同的是,deque还支持从开始端插入数据:push_front()。
使用deque容器之前必须加上
#include <deuqe>;
deque的初始化和销毁
deque<Elem> c //创建一个空的deque
deque<Elem> c1(c2) //复制一个deque
deque<Elem> c(n) //创建一个deque,含有n个数据,数据均已缺省构造产生
deque<Elem> c(n,elem) //创建一个含有n个elem拷贝的deque。
~deque<Elem>() //销毁所有数据,释放内存。
int arr[5]={1,2,3,4,5};
deque<int> d(arr,arr+5);
返回第一个元素的迭代器和最后一个元素的迭代器
int arr[5]={1,2,3,4,5};
deque<int> d(arr,arr+5);
deque<int>::iterator it;
for(it=d.begin();it!=d.end();it++){
cout << *it << " ";
}
cout<<endl;
operator=赋值运算符重载
int arr[5]={1,2,3,4,5};
deque<int> d1(arr,arr+5),d2;
d2 = d1;
c.empty()判断c容器是否为空
返回第一个元素和最后一个元素
c.front()返回c容器的第一个元素;
c.back()返回c容器的最后一个元素;
返回元素的个数
c.size()返回c容器中实际拥有的元素个数。
插入操作
c.insert(pos,num)在pos位置插入元素num。
c.insert(pos,n,num)在pos位置插入n个元素num。
c.insert(pos,beg,end)在pos位置插入区间为[beg,end)的元素。
删除操作
c.erase(pos)删除pos位置的元素;
c.erase(beg,end)删除区间为[beg,end)之间的元素;
开头、结尾的插入和删除操作(和vector不一样之处)
c.push_back(num)在末尾位置插入元素;
c.pop_back()删除末尾位置的元素;
c.push_front(num)在开头位置插入元素;
c.pop_front()删除开头位置的元素;
c1.swap(c2)交换容器c1,c2
deque的总结
deque是一个“双向队列(double-ended queue)”。这意味着从队列开始和结束处插入(删除)数据的性能很好。为了达到这个目的,deque基于一种分段连续的、介于数组和链表之间的数据结构。主要原理是把数组分段化,在分段的数组上添加指针来把所有段连在一起,最终成为一个大的数组。
deque和list一样,提供了push_back,push_front,pop_back,pop_front四个方法。可以想象,如果要对deque的两端进行操作,也就是要对第一段和最后一段的定长数组进行重新分配内存区,由于分过段的数组很小,重新分配的开销也就不会很大。
deque也和vector一样,提供了at和[]运算符的方法。要计算出某个数据的地址的话,虽然要比vector麻烦一点,但效率要比list高多了。首先和list一样进行遍历,每次遍历的时候累积每段数组的大小,当遍历到某个段,而且baseN <= index < baseN + baseN_length的时候,通过address = baseN + baseN_index就能计算出地址由于分过段的后链表的长度也不是很长,所以遍历对于整体性能的影响就微乎其微了。
双端队列(double-end queue) deque是在功能上合并了vector和list。 优点:
(1) 随机访问方便,即支持[ ]操作符和vector.at()
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:
(1) 占用内存多
deque的内存分布:
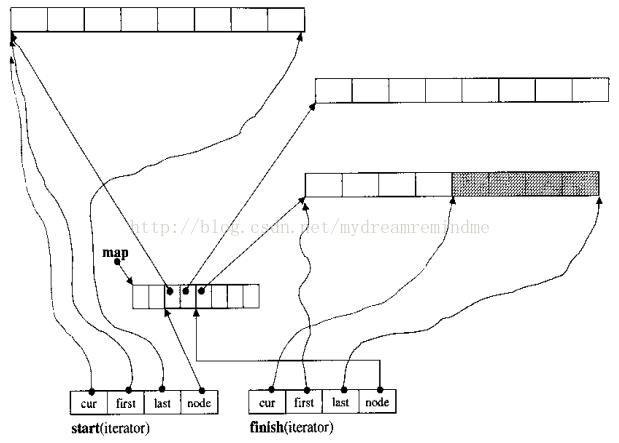
deque是逻辑上连续的地址空间,只是逻辑上的,并不向vector那样物理上就是连续的地址空间,严格的来说,deque的内存是一序列不连续的段组成,但是每个段都是物理上连续的地址。掌控这些段的中心是一个Map(这并不是stl中的map容器),它也是一个连续的空间,每个元素都是一个指针,它指向的位置就是每个段(缓冲区)。
STL容器使用区别
1 如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector(连续数组);
2 如果你需要大量的插入和删除,而不关心随即存取,则应使用list(双向循环链表);
3 如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque(双向队列);
4、如果打算存储数据字典,并且要求方便地根据key找到value,一对一的情况使用map,一对多的情况使用multimap;
5、如果打算查找一个元素是否存在于某集合中,唯一存在的情况使用set,不唯一存在的情况使用multiset。
STL-map
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。
这里说下map内部数据的组织,map内部自建一颗红黑树(一种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的,后边我们会见识到有序的好处。
什么是一对一的数据映射。比如一个班级中,每个学生的学号跟他的姓名就存在着一一映射的关系,这个模型用map可能轻易描述,很明显学号(int描述)+姓名(字符串描述):
map初始化
Map的构造函数:
map<int,string> mapStudent;
map数据插入
在构造map容器后,我们就可以往里面插入数据了。
第一种:用insert函数插入pair数据;
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent.insert(pair<int,string>(1,"student_one"));
mapStudent.insert(pair<int, string>(2,"student_two"));
mapStudent.insert(pair<int, string>(3,"student_three"));
map<int, string>::iterator iter; //声明迭代器
for(iter = mapStudent.begin();iter != mapStudent.end();iter++){
cout<<iter->first<<" "<<iter->second<<endl;
}
system("pause");
}
第二种:用insert函数插入value_type数据。
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent.insert(map<int, string>::value_type (1,"student_one"));
mapStudent.insert(map<int, string>::value_type (2,"student_two"));
mapStudent.insert(map<int, string>::value_type (3,"student_three"));
map<int, string>::iterator iter; //声明迭代器
for(iter = mapStudent.begin();iter != mapStudent.end();iter++){
cout<<iter->first<<" "<<iter->second<<endl;
}
system("pause");
}
第三种:用数组方式插入数据:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent[1] = "student_one";
mapStudent[2] = "student_two";
mapStudent[3] = "student_three";
map<int, string>::iterator iter; //声明迭代器
for(iter = mapStudent.begin();iter != mapStudent.end();iter++){
cout<<iter->first<<" "<<iter->second<<endl;
}
system("pause");
}
#include <map>
#include <iostream>
using namespace std;
int main(){
map<const char*,int> months;
months["january"] = 31;
months["february"] = 28;
months["march"] = 31;
months["april"] = 30;
months["may"] = 31;
months["june"] = 30;
months["july"] = 31;
months["august"] = 31;
months["september"] = 30;
months["october"] = 31;
months["november"] = 30;
months["december"] = 31;
map<const char*,int>::iterator it;
for(it=months.begin();it!=months.end();it++)
cout<<it->first<<" "<<it->second<<endl;
system("pause");
}
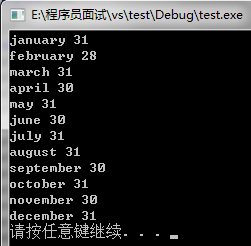
可以看出是无序的,这是因为默认的排序函数只能给int类型数据进行排序,不能对其他数据类型进行排序,因此必须自定义结构体类型(结构体中重载运算符()比较函数)来进行排序:
#include <map>
#include <iostream>
using namespace std;
struct ltstr{
bool operator()(const char* s1, const char* s2) const{
return strcmp(s1,s2)<0;
}
};
int main(){
map<const char*,int,ltstr> months;
months["january"] = 31;
months["february"] = 28;
months["march"] = 31;
months["april"] = 30;
months["may"] = 31;
months["june"] = 30;
months["july"] = 31;
months["august"] = 31;
months["september"] = 30;
months["october"] = 31;
months["november"] = 30;
months["december"] = 31;
map<const char*,int,ltstr>::iterator it;
for(it=months.begin();it!=months.end();it++)
cout<<it->first<<" "<<it->second<<endl;
system("pause");
}
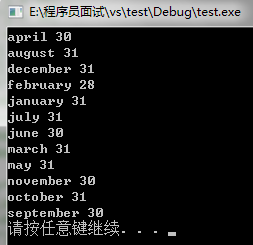
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是无法将数据插入的,但是用数组方式就不同了,它可以覆盖以前该关键字对应的值,用程序说明:
mapStudent.insert(map<int,string>::value_type (1,"student_one"));
mapStudent.insert(map<int,string>::value_type (1,"student_two"));
上面这两条语句执行后,map中1这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下:
pair<map<int, string>::iterator,bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (1,"student_one"));
下面代码演示插入成功与否问题:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
pair<map<int,string>::iterator,bool> Insert_Pair;
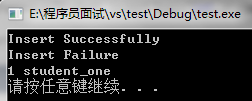
Insert_Pair=mapStudent.insert(pair<int,string>(1,"student_one")); //插入数据
if(Insert_Pair.second == true){ //判断是否插入成功
cout<<"Insert Successfully"<<endl;
}else{
cout<<"Insert Failure"<<endl;
}
Insert_Pair=mapStudent.insert(pair<int,string>(1,"student_two")); //插入数据
if(Insert_Pair.second == true){ //判断是否插入成功
cout<<"Insert Successfully"<<endl;
}else{
cout<<"Insert Failure"<<endl;
}
map<int,string>::iterator iter; //map迭代器
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++) //打印map中的东西
cout<<iter->first<<" "<<iter->second<<endl;
system("pause");
}
用数组插入在数据覆盖上的效果:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent[1] = "student_one";
mapStudent[1] = "student_two";
mapStudent[2] = "student_three";
map<int,string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<<iter->first<<" "<<iter->second<<endl;
system("pause");
}

map的大小
可以用size函数,用法如下:
Int nSize = mapStudent.size();
map数据的遍历
迭代方式:
//应用前向迭代器
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++){}
//应用反相迭代器
for(iter = mapStudent.rbegin(); iter != mapStudent.rend(); iter++){}
数组方式:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent.insert(pair<int,string>(1,"student_one"));
mapStudent.insert(pair<int, string>(2,"student_two"));
mapStudent.insert(pair<int, string>(3,"student_three"));
int nSize = mapStudent.size();
for(int nIndex = 1; nIndex <= nSize; nIndex++)
cout<<mapStudent[nIndex]<<endl;
system("pause");
}
数据的查找(包括判定这个关键字是否在map中出现)
使用find函数实现查找:
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
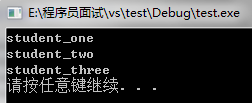
map<int,string> mapStudent;
mapStudent.insert(pair<int,string>(1,"student_one"));
mapStudent.insert(pair<int,string>(2,"student_two"));
mapStudent.insert(pair<int,string>(3,"student_three"));
map<int,string>::iterator iter;
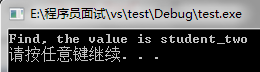
iter = mapStudent.find(2);
if(iter != mapStudent.end()){
cout<<"Find, the value is "<<iter->second<<endl;
}else{
cout<<"Do not Find"<<endl;
}
system("pause");
}
数据的清空与判空
清空map中的数据可以用clear()函数;
判定map中是否有数据可以用empty()函数,它返回true则说明是空map;
数据的删除
要用到erase函数,它有三个重载了的函数。
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<int,string> mapStudent;
mapStudent.insert(pair<int,string>(1,"student_one"));
mapStudent.insert(pair<int,string>(2,"student_two"));
mapStudent.insert(pair<int,string>(3,"student_three"));
//如果要删除1,用迭代器删除
map<int,string>::iterator iter;
iter = mapStudent.find(1);
mapStudent.erase(iter);
//如果要删除1,用关键字删除
int n = mapStudent.erase(1); //如果删除了会返回1,否则返回0
//用迭代器,成片的删除 以下代码把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
for(iter=mapStudent.begin();iter!=mapStudent.end();iter++)
cout<<iter->first<<" "<<iter->second<<endl;
system("pause");
}
map总结
map类似于数据库中的1:1关系,它是一种关联容器,提供一对一(C++ primer中文版中将第一个译为键,每个键只能在map中出现一次,第二个被译为该键对应的值)的数据处理能力,这种特性了使得map类似于数据结构里的红黑二叉树。
map应用例子
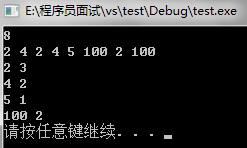
1.某次张国庆脑袋抽筋时想到了n个自然数,每个数均不超过1500000000(1.5*109)。已知不相同的数不超过10000个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺序输出统计结果。
输入包含n+1行:
第1行是整数n,表示自然数的个数。
第2~n+1行每行一个自然数。
输入:
8
2
4
2
4
5
100
2
100
输出:
2 3
4 2
5 1
100 2
#include <iostream>
#include <map>
using namespace std;
int main(){
int n;
cin>>n;
map<int,int> mapNum;
for(int i=0;i<n;i++){
int num;
cin>>num;
mapNum[num]++;
}
map<int,int>::iterator it;
for(it=mapNum.begin();it!=mapNum.end();it++)
cout<<it->first<<" "<<it->second<<endl;
system("pause");
}
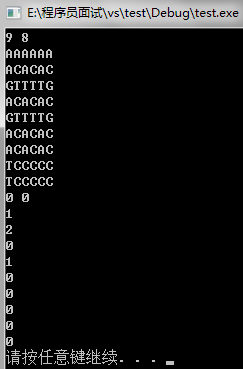
2.得克萨斯州的一个小镇Doubleville,被外星人攻击。他们绑架了当地人并把他们带到飞船里。经过一番(相当不愉快的)人体实验,外星人克隆了一些受害者,并释放了其中的多个副本回Doubleville。所以,现在有可能发生有6个人:原来的人和5个复制品都叫做Hugh F.Bumblebee。现在FBUC美国联邦调查局命令你负责确定每个人被复制了多少份,为了帮助您完成任务,FBUC收集每个人的DNA样本。同副本和原来的人具有相同的DNA序列,不同的人有不同的序列(我们知道,城里没有同卵双胞胎,这不是问题)
Input
输入中含有多组数据,每一组以一行n m开始,表示共有n个人1 ≤ n ≤ 20000,其中DNA序列长度为m, 1 ≤ m ≤ 20. 接下来的n行为DNA序列:每行包含m个字符,字符为’A’,’C’,’G’或’T’。 输入以n=m=0 结尾。
Output
每一组数据应输出n行,每行一个整数。第一行表示有几个人没有被复制,第二行表示有几个人只被复制一次(也就是说有两个相同的人),第三行表示有几个是被 复制两次,依次类推,第i行表示其中有i个相同的人的共有几组。举例来说,如果有11个样本,其中之一是John Smith,和所有其余的都是从Joe Foobar复制来的副本,那么你必须打印第一行和第10行输出1,其余行输出0。
Sample Input:
9 6
AAAAAA
ACACAC
GTTTTG
ACACAC
GTTTTG
ACACAC
ACACAC
TCCCCC
TCCCCC
0 0
Sample Output:
1
2
0
1
0
0
0
0
0
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
int n,m;
cin>>n>>m;
map<string,int> mapStr;
for(int i=0;i<n;i++){
string str;
cin>>str;
mapStr[str]++;
}
int n1,m1;
cin>>n1>>m1;
map<string,int>::iterator it;
map<int,int> mapCount;
for(it=mapStr.begin();it!=mapStr.end();it++){
mapCount[it->second-1]++;
}
int *arr=(int*)malloc(n*sizeof(int)); //记录数组
for(int i=0;i<n;i++)
arr[i]=0;
map<int,int>::iterator it1;
for(it1=mapCount.begin();it1!=mapCount.end();it1++)
arr[it1->first]=it1->second;
for(int i=0;i<n;i++)
cout<<arr[i]<<endl;
system("pause");
}
map的按Key排序和按Value排序
map是用来存放<key,value>键值对的数据结构,可以很方便快速的根据key查到相应的value。假如存储学生和其成绩(假定不存在重名,当然可以对重名加以区分),我们用map来进行存储就是个不错的选择。 我们这样定义,map<string, int>,其中学生姓名用string类型,作为Key;该学生的成绩用int类型,作为value。这样一来,我们可以根据学生姓名快速的查找到他的成绩。
如果要按照学生姓名的顺序进行输出,或者按照学生成绩的高低进行输出。换句话说,我们希望能够对map进行按Key排序或按Value排序,然后按序输出其键值对的内容。
按Key排序
其实,为了实现快速查找,map内部本身就是按序存储的(比如红黑树)。在我们插入<key,value>键值对时,就会按照key的大小顺序进行存储。
#include <map>
#include <string>
#include <iostream>
using namespace std;
typedef pair<string, int> PAIR;
ostream& operator<<(ostream& out, const PAIR& p){ //运算符重载
return out<<p.first<<" "<< p.second;
}
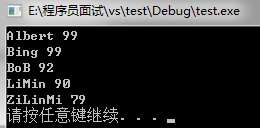
int main(){
map<string, int> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map["Bing"] = 99;
name_score_map["Albert"] = 99;
map<string, int>::iterator iter;
for(iter = name_score_map.begin();iter != name_score_map.end();++iter){
cout<<*iter<< endl;
}
system("pause");
}
map是stl里面的一个模板类,map的定义如下:
template < class Key, class T, class Compare = less<Key>,
class Allocator = allocator<pair<const Key,T> > > class map;
比较熟悉的有两个: Key和Value。第四个是Allocator,用来定义存储分配模型的,这里不作讨论。重点是第三个参数:class Compare = less<Key>。
这也是一个class类型的,而且提供了默认值 less
less的实现:
template <class T> struct less : binary_function <T,T,bool>{
bool operator()(const T& x,const T& y) const{
return x<y;
}
};
它是一个带模板的struct,里面仅仅对()运算符进行了重载,实现很简单,但用起来很方便,这就是函数对象的优点所在。stl中还为四则运算等常见运算定义了这样的函数对象,与less相对的还有greater:
template <class T> struct greater : binary_function <T,T,bool>{
bool operator() (const T& x,const T& y) const{
return x>y;
}
};
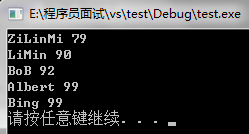
map这里指定less作为其默认比较函数(对象),所以我们通常如果不自己指定Compare,map中键值对就会按照Key的less顺序进行组织存储,因此我们就看到了上面代码输出结果是按照学生姓名的字典顺序输出的,即string的less序列。
#include <map>
#include <string>
#include <iostream>
using namespace std;
typedef pair<string, int> PAIR;
ostream& operator<<(ostream& out, const PAIR& p){ //运算符重载
return out<<p.first<<" "<< p.second;
}
int main(){
map<string, int,greater<string>> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map["Bing"] = 99;
name_score_map["Albert"] = 99;
map<string, int,greater<string>>::iterator iter;
for(iter = name_score_map.begin();iter != name_score_map.end();++iter){
cout<<*iter<< endl;
}
system("pause");
}
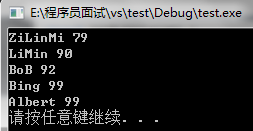
如果我们想自己写一个compare的类,让map按照我们想要的顺序来存储,比如,按照学生姓名的长短排序进行存储,那该怎么做呢?其实很简单,只要我们自己写一个函数对象,实现想要的逻辑,定义map的时候把Compare指定为我们自己编写的这个就ok啦。
#include <map>
#include <string>
#include <iostream>
using namespace std;
typedef pair<string, int> PAIR;
ostream& operator<<(ostream& out, const PAIR& p){ //运算符重载
return out<<p.first<<" "<< p.second;
}
struct CmpByKeyLength{
bool operator()(const string& k1, const string& k2){
return k1.length() < k2.length();
}
};
int main(){
map<string, int,CmpByKeyLength> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map["Bing"] = 99;
name_score_map["Albert"] = 99;
map<string, int,CmpByKeyLength>::iterator iter;
for(iter = name_score_map.begin();iter != name_score_map.end();++iter){
cout<<*iter<< endl;
}
system("pause");
}
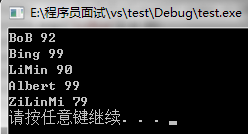
按Value排序
在第一部分中,我们借助map提供的参数接口,为它指定相应Compare类,就可以实现对map按Key排序,是在创建map并不断的向其中添加元素的过程中就会完成排序。
现在我们想要从map中得到学生按成绩的从低到高的次序输出,该如何实现呢?换句话说,该如何实现Map的按Value排序呢?
第一反应是利用stl中提供的sort算法实现,这个想法是好的,不幸的是,sort算法有个限制,利用sort算法只能对序列容器进行排序,就是线性的(如vector,list,deque)。map也是一个集合容器,它里面存储的元素是pair,但是它不是线性存储的(前面提过,像红黑树),所以利用sort不能直接和map结合进行排序。
虽然不能直接用sort对map进行排序,那么我们可不可以迂回一下,把map中的元素放到序列容器(如vector)中,然后再对这些元素进行排序。
#include <map>
#include <string>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<string, int> PAIR;
ostream& operator<<(ostream& out, const PAIR& p){ //运算符重载
return out<<p.first<<" "<< p.second;
}
bool CmpByValue(const PAIR &p1,const PAIR &p2){
return p1.second<p2.second;
}
int main(){
map<string, int> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map["Bing"] = 99;
name_score_map["Albert"] = 99;
//把map中元素转存到vector中
vector<PAIR> name_score_vec(name_score_map.begin(),name_score_map.end());
sort(name_score_vec.begin(),name_score_vec.end(),CmpByValue);
for (int i = 0; i != name_score_vec.size(); ++i){
cout<<name_score_vec[i]<<endl;
}
system("pause");
}
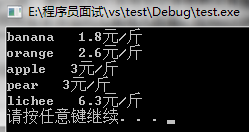
multimap多重映照容器
multimap与map一样,都是使用红黑树对记录型的元素数据,按元素键值的比较关系,进行快速的插入、删除和检索操作,所不同的是 multimap 允许将具有重复键值的元素插入容器。在multimap容器中,元素的键值与元素的映照数据的映照关系,是多对多的,因此,multimap称为多重映照容器。multimap与map之间的多重特性差异,类似于multiset与set的多重特性差异。
multimap与map容器共用同一个C++标准头文件:#include <map>
不同于map容器,multimap容器只能采用迭代器的方式,而不能用数组方式遍历容器的元素。迭代器方式的元素访问,一般要用begin和end函数找出遍历开始的首元素和结束元素,然后通过迭代器的 “++” 和 “*“ 操作取出元素。
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main(){
multimap<float, string> mm;
mm.insert(pair<float,string>(3.0f,"apple"));
mm.insert(pair<float,string>(3.0f,"pear"));
mm.insert(pair<float,string>(2.6f,"orange"));
mm.insert(pair<float,string>(1.8f,"banana"));
mm.insert(pair<float,string>(6.3f,"lichee"));
//遍历打印
multimap<float,string>::iterator i,iend;
iend = mm.end();
for(i=mm.begin();i!=iend;++i)
cout <<i->second <<" "<<i->first<<"元/斤 \n";
system("pause");
}
由于键值允许重复插入,在multimap容器中具有同一个键值的元素有可能不只一个。因此,multimap容器的find函数将返回第一个搜索到的元素位置,如果元素不存在,则返回end结束元素位置。
总结:
multimap多重映照容器也是一种依元素键值进行插入、删除和检索的有序关联容器,元素的检索具有对数阶的算法时间复杂度。与map容器的区别是,multimap允许元素键值出现重复,这导致multimap多重映照容器不能像map容器那样,可简便地利用数组方式访问或添加容器元素。
multimap缺点:和map的缺点差不多。multimap是比较复杂的用法,如果能用vector 、list这些容器完成的事情,就不需要用到multimap。
multimap优点:相比map ,multimap能允许重复键值的元素插入。
STL-set
C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像vector, string, list等方便的容器,更重要的是STL封装了许多复杂的数据结构算法和大量常用数据结构操作。vector封装数组,list封装了链表,map和set封装了二叉树等,在封装这些数据结构的时候,STL按照程序员的使用习惯,以成员函数方式提供的常用操作,如:插入、排序、删除、查找等。让用户在STL使用过程中,并不会感到陌生。
关于set,必须说明的是set关联式容器。set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。
set常用函数
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s; //初始化
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(1);
cout<<"set 的 size 值为 :"<<s.size()<<endl;
cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl;
set<int>::iterator it;
it=s.begin();
cout<<"set 中的第一个元素是 :"<<*it<<endl;
it=s.end();
it--;
cout<<"set 中的最后一个元素是:"<<*it<<endl;
s.clear();
if(s.empty()){
cout<<"set 为空 !!!"<<endl;
}
cout<<"set 的 size 值为 :"<<s.size()<<endl;
cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl;
system("pause");
}
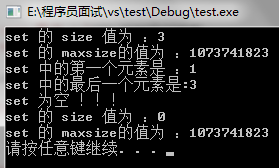
插入3之后虽然插入了一个1,但是我们发现set中最后一个值仍然是3,这就是set。
count()
count()用来查找set中某个某个键值出现的次数。这个函数在set并不是很实用,因为一个键值在set只可能出现0或1次,这样就变成了判断某一键值是否在set出现过了。
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(1);
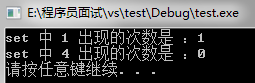
cout<<"set 中 1 出现的次数是 :"<<s.count(1)<<endl;
cout<<"set 中 4 出现的次数是 :"<<s.count(4)<<endl;
system("pause");
}
equal_range()
返回一对定位器,分别表示第一个大于或等于给定关键值的元素和 第一个大于给定关键值的元素,这个返回值是一个pair类型,如果这一对定位器中哪个返回失败,就会等于end()的值。
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s;
set<int>::iterator iter;
for(int i = 1 ; i <= 5; ++i){
s.insert(i);
}
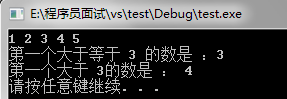
for(iter = s.begin() ; iter != s.end() ; ++iter){
cout<<*iter<<" ";
}
cout<<endl;
pair<set<int>::const_iterator,set<int>::const_iterator> pr;
pr = s.equal_range(3);
cout<<"第一个大于等于 3 的数是 :"<<*pr.first<<endl;
cout<<"第一个大于 3的数是 : "<<*pr.second<<endl;
system("pause");
}
删除
erase(iterator),删除定位器iterator指向的值;
erase(first,second),删除定位器first和second之间的值;
erase(key_value),删除键值key_value的值;
#include <iostream>
#include <set>
using namespace std;
int main(){
set<int> s;
set<int>::const_iterator iter;
set<int>::iterator first;
set<int>::iterator second;
for(int i = 1 ; i <= 10 ; ++i){
s.insert(i);
}
//第一种删除
s.erase(s.begin());
//第二种删除
first = s.begin();
second = s.begin();
second++;
second++;
s.erase(first,second);
//第三种删除
s.erase(8);
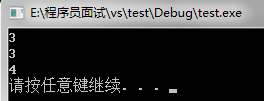
cout<<"删除后 set 中元素是 :";
for(iter = s.begin() ; iter != s.end() ; ++iter){
cout<<*iter<<" ";
}
cout<<endl;
system("pause");
}
find()
返回给定值值得定位器,如果没找到则返回end()。
#include <iostream>
#include <set>
using namespace std;
int main()
{
int a[] = {1,2,3};
set<int> s(a,a+3);
set<int>::iterator iter;
if((iter = s.find(2)) != s.end()){
cout<<*iter<<endl;
}
system("pause");
}
插入
insert(key_value);
将key_value插入到set中,返回值是pair<set
inset(first,second);
将定位器first到second之间的元素插入到set中,返回值是void。
lower_bound和upper_bound
lower_bound(key_value) ,返回第一个大于等于key_value的定位器;
upper_bound(key_value),返回最后一个大于等于key_value的定位器;
#include <iostream>
#include <set>
using namespace std;
int main(){
set<int> s;
s.insert(1);
s.insert(3);
s.insert(4);
cout<<*s.lower_bound(2)<<endl;
cout<<*s.lower_bound(3)<<endl;
cout<<*s.upper_bound(3)<<endl;
system("pause");
}
自定义排序函数
set/multiset会根据待定的排序准则,自动将元素排序。两者不同在于前者不允许元素重复,而后者允许。
1) 不能直接改变元素值,因为那样会打乱原本正确的顺序,要改变元素值必须先删除旧元素,则插入新元素
2) 不提供直接存取元素的任何操作函数,只能通过迭代器进行间接存取,而且从迭代器角度来看,元素值是常数
3) 元素比较动作只能用于型别相同的容器(即元素和排序准则必须相同)
set模板原型://Key为元素(键值)类型
template <class Key, class Compare=less<Key>, class Alloc=STL_DEFAULT_ALLOCATOR(Key) >
从原型可以看出,可以看出比较函数对象及内存分配器采用的是默认参数,因此如果未指定,它们将采用系统默认方式, 另外,利用原型,可以有效地辅助分析创建对象的几种方式。
#include <iostream>
#include <set>
#include <string>
using namespace std;
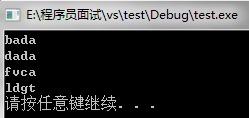
int main(){
set<string> setstr;
setstr.insert("ldgt");
setstr.insert("fvca");
setstr.insert("bada");
setstr.insert("dada");
set<string>::iterator i;
for(i=setstr.begin();i!=setstr.end();i++)
cout<<*i<<endl;
system("pause");
}
#include <iostream>
#include <set>
#include <string>
using namespace std;
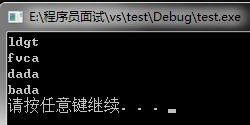
struct cmp{
bool operator()(string str1,string str2){
return str1>str2;
}
};
int main(){
set<string,cmp> setstr;
setstr.insert("ldgt");
setstr.insert("fvca");
setstr.insert("bada");
setstr.insert("dada");
set<string,cmp>::iterator i;
for(i=setstr.begin();i!=setstr.end();i++)
cout<<*i<<endl;
system("pause");
}
stack
stack 模板类的定义在
stack 模板类需要两个模板参数,一个是元素类型,一个容器类型,但只有元素类型是必要的,在不指定容器类型时,默认的容器类型为deque。
定义stack 对象的示例代码如下:
stack<int> s1;
stack<string> s2;
stack 的基本操作有:
入栈,如例:s.push(x);
出栈,如例:s.pop();注意,出栈操作只是删除栈顶元素,并不返回该元素。
访问栈顶,如例:s.top()
判断栈空,如例:s.empty(),当栈空时,返回true。
访问栈中的元素个数,如例:s.size()。
queue
queue 模板类的定义在
与stack 模板类很相似,queue 模板类也需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque类型。
定义queue 对象的示例代码如下:
queue<int> q1;
queue<double> q2;
queue 的基本操作有:
入队,如例:q.push(x); 将x 接到队列的末端。
出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。
访问队首元素,如例:q.front(),即最早被压入队列的元素。
访问队尾元素,如例:q.back(),即最后被压入队列的元素。
判断队列空,如例:q.empty(),当队列空时,返回true。
访问队列中的元素个数,如例:q.size()