在学习数据库之前,必须了解数据库最常用的一些基本术语。
数据、数据库、数据库管理系统、数据库系统
数据
数据是数据库中存储的基本对象。描述事物的符号记录称为数据。描述事物的符号可以是数字,也可是文字、图形、图像、声音、语言等等。数据是有结构的,有多种表现形式,它们都可以经过数字化后存入计算机。
数据库
数据库,顾名思义,是存放数据的仓库。只不过这个仓库是在计算机存储设备上,而且数据是按照一定的格式存放的。严格地讲,数据库是长期存储在计算机内、有组织的、可共享的大量数据的集合。
数据库管理系统
如何科学地组织和存储数据,如何高效地获取和维护数据,完成这个任务就是数据库管理系统。数据库管理系统是位于用户与操作系统之间的一层数据管理软件,和操作系统一样是计算机的基础软件。
数据库系统
数据库系统是指计算机引入数据后的系统,一般由数据库、数据库管理系统、应用系统、数据库管理员构成。数据库的建立、使用和维护等工作只靠一个数据库管理系统还远远不够,还要有专门的人员来完成,这些人被称为数据库管理员。
数据模型
数据模型是用来描述数据、组织数据和对数据进行操作的。
主要用两类数据模型描述数据:
第一类:概念模型;
第二类:逻辑模型,包括层次模型、网状模型、关系模型等等。
数据模型的组成部分
1.数据结构;
2.数据操作,主要有查询和更新(包括插入、删除和修改)两大类;
3.数据的完整性约束条件,数据模型必须遵守基本的完整性约束条件,比如某大学的数据库规定教授的退休年龄是65周岁,男职工的退休年龄是60岁,女职工的退休年龄是55岁。
概念模型
1.实体。客观存在并可相互区别的事物称为实体,如人、事、物。
2.属性。实体所具有的某一特性称为属性。一个实体可以由若干个属性来刻画。例如学生实体可以由学号、姓名、性别、出生年月等属性组成,这些属性组合起来表征了一个学生。
3.码(键)。唯一标识实体的属性集称为码。例如学号是学生实体的码。
4.域。域是一组具有相同数据类型的值的集合。属性的取值范围来自某个域。例如学号域为8位整数,姓名的域为字符串集合。
5.实体型。具有相同属性的实体必然具有共同的特征和性质,称之为实体型。例如,学生(学号,姓名,性别,出生年月,所在院系,入学时间)就是一个实体型。
6.实体集。同一类型实体的集合称为实体集。例如,全体学生就是一个实体集。
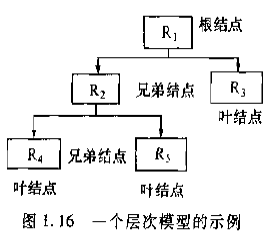
层次模型
层次模型是数据库系统中最早出现的数据模型,层次数据模型系统采用层次模型作为数据的形式。
层次模型数据结构:
1.有且只有一个结点没有双亲结点,这个结点称为根结点;
2.根以外的其他结点有且只有一个双亲结点;
层次模型的优点:
1.层次模型的数据结构比较简单清晰;
2.层次数据库的查询效率高;
层次模型的缺点:
现实世界中很多联系是非层次性,如结点之间具有多对多联系,层次模型表示这类的方法很笨拙。
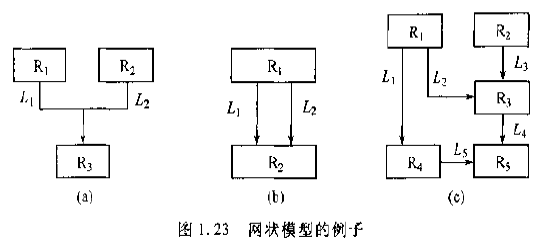
网状模型
在现实世界中事物之间的联系更多是非层次关系,用层次模型表示非树形结构是很不直接的,网状模型则可以克服这一弊病。
网状模型数据结构:
1.允许一个以上的结点无双亲;
2.一个结点可以有多于一个的双亲;
网状数据模型的优点:
1.能够更为直接地描述现实世界;
2.具有良好的性能,存取效率高;
网状数据模型的缺点:
结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握。由于记录之间联系是通过存取路径实现的,应用程序在访问数据时必须选择适当的存取路径,因此,用户必须了解系统结构的细节,加重了编写应用程序的负担。
关系模型
关系模型为人们提供了单一的一种描述数据的方法:一个称之为关系的二维表。如下图中就是一个关系的例子,该关系名为Movies,关系中的每一行对应一部电影实体,每一列对应电影实体的一个特征。
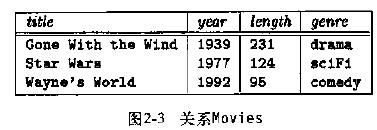
属性:关系的列命名为属性,如图2-3中的属性分别是title、year、length和genre,通常属性用来描述所在列的项目的语义。
模式:关系名和其属性集合的组合称为这个关系的模式。描述一个关系模式时,先给出一个关系名,其后是用圆括号括起的所有属性:
Movies(title,year,length,genre)
在关系模型中,数据库是由一个或多个关系组成。数据库的关系模式集合称为数据库模式。通常约定,关系名以大写字母开头,属性名以小写字母开头。
元组:关系中除含有属性名所在行以外的其他行都称作元组。每个元组均有一个分量对应于关系的每个属性。
域:关系模型要求元组的每个分量具有原子性。也就是说,它必须属于某种元素类型,如integer或string,而不能是记录、集合、列表、数组或其他任何可以被分解成更小分量的组合类型。关系Movies中四个分量对应的域分别是:string、integer、integer、string。因此可以使用如下方式来描述关系Movies的模式:
Movies(title:string,year:integer,length:integer,genre:string)
关系上的键
在关系模式中,可以对数据库模式的关系加很多约束。一种非常基本的约束:键约束。键由关系的一组属性集组成,通过定义键可以保证关系实例上任何两个元组的值定义键的属性集上取值不同。
例如:关系Movies上的键由两个属性组成:title和year。也就是说,没有两部电影的制作年份和名字均相同。注意,单独的title属性并不构成一个键,因为不同年份制作的电影名可能相同。
通常在形成键的属性后属性组下面画上下划线,用来表明它是键的组成部分,例如关系Movies的模式可以写成:
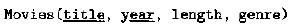
形成键的属性集的值对于关系的所有实例都具有唯一性。现实生活中的数据库经常使用虚拟键,这样可以安全地对属性值做出所需要的假定。例如公司通常会为每个雇员指派一个员工ID,该ID是具有唯一性的数字,这样雇员的ID属性就可以作为公司雇员关系的键。
创建一个属性用来作为键的思想在现实生活中应用得很广泛,除了员工的ID外,还有大学中用学生ID来区分每个学生,分别用驾驶执照号和机动车注册号来区分每个驾驶员和每辆机动车。
数据库模式实例
1.电影:

2.电影明星:

3.演出:

4.电影制片:

5.电影公司:

SQL语言
SQL语言介绍
最普片用于描述和操作关系数据库的语言是SQL语言(读作“sequal”)。最新的SQL标准称为SQL-99。现今的大多数商用数据库管理系统都只是实现了标准的一部分,而不是全部实现。
SQL语言有两方面的内容:
1.用于定义数据库模式的数据定义子语言;
2.用于查询和更新数据库的数据操纵子语言;
两种子语言的区别在大多数的程序语言中都可以找到,例如,在C和Java语言里,既有定义数据的部分,也有代码执行的部分,它们分别对应于SQL的数据定义子语言和数据操纵子语言。
存储的关系称为表,这是通常要处理的一种关系,它在数据库中存储,用户能够对其元组进行查询和更新。
SQL中的CREATE TABLE语句就是用来定义一个被存储的关系,它给出表的名字、属性及其数据类型,可以为关系定义一个甚至多个键。
SQL语言中数据类型
1.可变长度和固定长度的字符串
类型CHAR(n)表示最多为n个字符的固定长度字符串;
类型VARCHAR(n)也可表示最多为n个字符的字符串;
二者的区别在于CHAR类型会以一些短的字符串来填充后面未满的空间来构成n个字符;而VARCHAR类型会使用一个结束符或字符长度值来标志字符串结束,后面未满的空间不做填充。
2.固定或可变长度的位串
位串和字符串类似,但它们的值是由比特而不是字符组成。类型BIT(n)表示长为n的位串。
3.BOOLEAN表示具有逻辑类型的值
该类属性的可能值是TRUE、FALSE、UNKNOWN。
4.类型INT和INTEGER表示典型的数据值
类型SHORTINT也表示整数,但是表示的位数可能小一些,具体取决于现实。
5.浮点值能通过不同的方法表示
类型FLOAT、REAL均均表示典型的浮点数值,需要高精度的浮点类型可以使用DOUBLE PRECISION。
SQL中还提供指定小数点后位数的浮点数类型。例如DECIMAL(n,d)允许可以有n位有效数字的十进制数,小数点是在右数第d位的位置。比如:
0123.45就是符合类型DECIMAL(6,2)定义的数值。
6.日期和时间分别通过DATA和TIME数据类型表示
SQL简单表的定义
例如Movies的表定义:
CREATE TABLE Movies(
title CHAR(100),
year INT,
length INT,
genre CHAR(10),
studioName CHAR(30),
producerC# INT
);
例如MoviesStar的表定义:
CREATE TABLE MoviesStar)
name CHAR(30),
address VARCHAR(255),
gender CHAR(1),
birthdate DATE
);
修改SQL关系模式
删除某个关系R,可以使用如下的SQL语句:
DROP TABLE R;
对表的修改操作的语句以关键字ALTER TABLE开头其后加上关系的名字,后面还可以跟几种选项,最重要的两种为:
1.ADD后面加上属性名字和数据类型,添加新的属性列;
2.DROP后面加属性的名字,删除属性列;
例如修改MovieStart,给它增加属性phone,语句为:
ALTER TABLE MovieStart ADD phone CHAR(16);
语句的结果是MovieStart现在具有5个属性,该字段的值为空值NULL。
另一个ALTER TABLE语句是:
ALTER TABLE MovieStart DROP birthdate;
该语句结果是删除关系MovieStart中的birthdate属性。
默认值
当创建或修改元组时,并非总是给它的每个字段指定值。给关系增加一列时,关系中已存在的元组对应此列没有一个具体的值,通常建议使用NULL值来替代该位置上的值。但是有时候可能更愿意使用另外的默认值来替代NULL值。
通常,在任何声明属性和其数据类型的地方,都可以加上保留字DEFAULT和一个合适的值,该值一般要么是NULL,要么是常量。例如:希望使用字符“?”作为属性gender未知时的默认值。或者使用一个可能最早的日期DATE‘0000-00-00’作为某个未知birthdate的默认值。可以使用以下语句:
gender CHAR(1) DEFAULT '?',
birthdate DATE DEFAULT DATE '0000-00-00'
键的声明
CREATE TABLE语句在定义一个存储关系时,有两种方法将某个属性或某组属性声明为一个键。
1.当属性被列入关系模式时,声明其是键;
2.在模式声明的项目表中增加表项,声明一个或者一组属性是键。
有两种指明键的方法:
1.PRIMARY KEY;
2.UNIQUE;
对于关系R,使用PRIMARY KEY或者UNIQUE声明某组属性S为键的效果是:
R的任意两个元组不能在S的所在属性上具有完全相同的值,除非其中有一个是NULL值
除此之外,如果PRIMARY KEY被使用,则S中属性不能有NULL,违反该规则的操作将被DBMS拒绝。但是,如果S被声明为UNIQUE,则NULL的值被允许。这是两者的区别之一。例如下面以MovieStart为例。
name主键声明:
CREATE TABLE MoviesStar)
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
gender CHAR(1),
birthdate DATE
);
独立的主键声明:
CREATE TABLE MoviesStar)
name CHAR(30),
address VARCHAR(255),
gender CHAR(1),
birthdate DATE,
PRIMARY KEY (name)
);
比如在关系Movies中,键由一对属性title和year组成:
CREATE TABLE Movies(
title CHAR(100),
year INT,
length INT,
genre CHAR(10),
studioName CHAR(30),
producerC# INT,
PRIMARY KEY (title,year)
);