对于所有直接操作内衬的程序员来说,数据对齐是很重要的问题,数据对齐与否能对程序的正常运行造成影响。
内存存取粒度
程序员通常倾向认为内存就像一个字节数组,顺序、均匀地在内存空间线性地排列开来。如图所示:

理论上CPU处理器可以按一个字节为单位来存取内存,但它一般不着么做。假设CPU是一个32位的处理器,它一般会以双字节或者最多以四字节为单位来存取内存,我们把这些存取内存单位称为内存存取粒度。
至于计算机为什么存取内存一般采用一个字节以上的内存存取粒度,答案很简单:比如有一个4字节的变量,使用1个字节的内存存取粒度模式从内存读到CPU寄存器中需要四次读取操作:
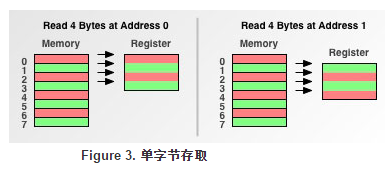
但是如果使用2个字节的内存存取粒度,仅需要两次读取操作,读取内存效率就会提高一倍。
内存存取粒度规定每一次访问数据的大小,同时对地址上也有限制。每一次访问的空间的首地址必须是内存存取粒度的倍数。比如内存存取粒度为4,只能访问这样的区间:
0x0 - 0x3, 0x4 - 0x7, 0x8 - 0xc
不能访问这样的区间:
0x1 - 0x4, 0x5 - 0x8, 0x6 - 0x9
因此在CPU处理器看来,内存是块为单位的:
字节对齐
假设机器子长是32位(4个字节),也就是处理任何内存中的数据,其实都是按32位的单位进行的,内存存取粒度为4。现在有2个变量:
char A;
int B;
假设这2个变量是从内存0开始分配的,理论上应该是这样存储的:

因为计算机的内存存取粒度为4,所以在处理变量A与B时的过程大致为:
A:将0x00-0x03共32位读入寄存器,在通过右移24位(或者与0x000000FF做与运算)得到a的值。
B:将0x00-0x03共32位读入寄存器,通过位运算符得到低24位的值;在将0x04-0x07这32位读入寄存器,通过位运算得到高8位的值;再与最先得到的24位做位运算,才可以得到整个32位的值。
由此可知,对a的处理是最简单的。可对b处理,本身是一个32位的数,处理的时候却得折成2部分,之后再合并,效率上就有些低了。
要解决这个问题,就需要付出几个字节浪费的代价:

按照上面的分配方式:A和B之间填充了3个空字节,A的处理过程不变,B却变得简单多:只需将0x04-0x07这32位读入寄存器即可,读取效率大为提高。这就是字节对齐。
字节对齐概念:因为计算机的内存空间都是按照字节来划分的,从理论上讲任何类型的变量访问可以从任何地址开始。但实际情况是在访问特定类型变量的时候,经常在特定的内存地址访问,这就需要各种类型数据要按照一定的规则在内存空间上排列,而不是顺序的一个接一个地排放。
字节对齐是为了在内存空间与复杂度上达到平衡的一种技术手段,简单地来说,是为了在可接受的空间浪费的前提下,尽可能地提高内存存取效率(相同运算过程的最快处理)。
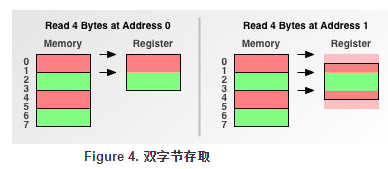
如图所示,内存存取粒度为4字节,左边表示把内存0x00-0x03的数据读到寄存器中,由于满足字节对齐状况,只需要一次读出操作;右边表示把内存0x01-0x04的数据读到寄存器中需要两次读取操作,还有额外的数据位运算,内存存储效率降低:

非对齐数据处理过程(把内存0x01-0x04的数据读到寄存器中):
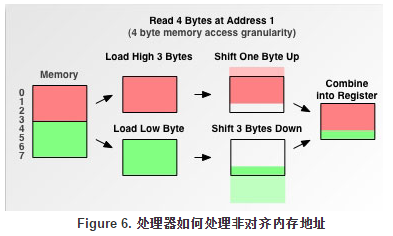
处理器先从非对齐地址读取第一个4字节块,剔除不想要的字节,然后读取下一个4字节块,同样剔除不要的数据,最后留下的两块数据合并放入寄存器,这需要做很多工作。
目前计算机一般是32位和64位,而64位是主流。因此内存存取粒度可以设置为1字节,2字节,4字节,最大为8字节。当把内存存取粒度设置为1字节,则不需要数据进行字节对齐,因为CPU在该模式下可以读取任何内存单元。当我们把内存存取粒度设置为2字节、4字节、8字节时,在内存中的数据也要按2字节对齐、4字节对齐、8字节对齐。在Window VS2010环境下,默认8字节对齐(内存存取粒度为8)。
结构体数据成员字节对齐
字节对齐主要是为了解决内存访问次数的问题,确保访问一个变量以最少的读取次数来完成访问过程。
例子1
假设内存存取粒度为4,有如下变量:
char a;
int b;
假设如图存放数据:
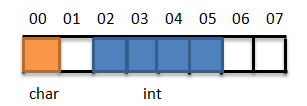
访问变量a,只需读取一次,访问变量b则需要读取两次(先读取0x00-0x03,再读取0x04-0x07,然后运算得到结果。
如果按如下图存放数据:
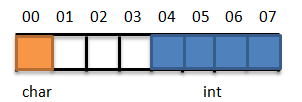
访问变量a,只需读取一次,访问变量b也只读取一次(只读取0x04-0x07)。
这就说明如果一个变量,如果跨越了4字节边界存储,那么cpu要读取两次,这样效率就会降低。在图中0x03-0x04就是一个4字节边界。因此必须尽可能避免跨越边界存储数据。
例子2
假设内存存取粒度还是为4,有如下变量:
char a;
double b;
假设如图存放数据:

访问变量a只需读取一次,访问变量b需要读取三次(先读取0x00-0x03,再读取0x04-0x07,最后读取0x08-0x0B),跨越4字节边界0x03-0x04和0x07-0x08存储两次。
如果按如下图存放数据:

访问变量a只需读取一次,访问变量b需要读取两次(读取0x04-0x07,再读取0x08-0x0B),读取次数变得最少(因为内存存取粒度为4,而double类型变量大小为8,因此至少需要两次读取),只跨越4字节边界0x07-0x08存储一次。
例子3
假设内存存取粒度为8,有如下变量:
char a;
double b;
必须按如下图存放数据:

才能做到访问变量a只需读取一次,访问变量b只需要读取1次(读取0x04-0x0B),读取次数最少(因为内存存取粒度为8,而double类型变量大小为8,因此至少只需要一次读取),没有跨越8字节边界存储。
例子4
假设内存存取粒度为8,有如下变量:
char a;
int b;
对于这种情况,变量b可以4字节对齐:

也可以8字节对齐:

无论是哪一种对齐方式,访问变量b都只需要读取一次,没有跨越8字节边界存储,但是明显4字节对齐比8字节对齐更有优势,因为4字节对齐浪费了3个字节的空间,而8字节却浪费了7个字节,因此,综合考虑内存空间浪费问题,我们选择MIN(内存存取粒度8,该数据成员的自身长度4) = 4来对齐。
总结
综上以上三个例子,对于一个结构体变量来说,假设结构体第一个数据成员从内存地址0x00开始:
字节对齐规则1:每个数据成员的偏移量必须是MIN(内存存取粒度n,该数据成员的自身长度)的倍数。
这条规则保证了跨越n字节边界存储的次数最少,读取操作也就最少,提高了内存读取效率。但是前提是结构体第一个数据成员的内存地址是0x00,现实情况是不可能的,因此引出第二条规则:
字节对齐规则2:结构体第一个数据成员的地址必须是MIN(内存存取粒度n,结构体中数据成员最大长度)的倍数。
至于为什么是结构体中数据成员最大长度,请看以下例子:
例子5
struct{
int a;
short b;
}
在这里int是4字节,short是2字节,假设结构体开始地址以2字节为倍数,如图所示:
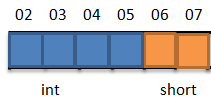
则b变量可以满足字节对齐规则1,但变量a无法满足字节对齐规则1。
假设结构体开始地址以4字节为倍数,如图所示:
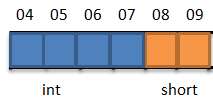
则变量a和b满足字节对齐规则1,
因此字节对齐规则2保证结构体后面每个数据成员的地址是MIN(内存存取粒度n,该数据成员的自身长度)的倍数。
例子6
以下代码在VS2010环境运行,内存存取粒度默认为8字节(默认8字节对齐):
struct T
{
char c; //本身长度1字节
__int64 d; //本身长度8字节
int e; //本身长度4字节
short f; //本身长度2字节
char g; //本身长度1字节
short h; //本身长度2字节
}stu;
分析:
代码中定义了结构体变量stu,假设在内存中分配到了00(0x00)的位置。
对于成员stu.c,只需一次寄存器读入,所以先占一个字节;
对于成员stu.d,是一个8字节的变量,如果紧跟着stu.c存储,则读入寄存器需要两次,因此按照8字节对齐存储,分配到08-15(0x08-0x0F),只需一次寄存器读入;
对于变量stu.e,是一个4字节的变量,4字节对齐即可,分配到16-19(0x10-0x13)单元中,只需一次寄存器读入;
对于成员stu.f,是一个2字节的变量,2字节对齐即可,分配到20-21(0x14-0x15)单元中,只需一次寄存器读入;
对于成员stu.g,是一个1字节的变量,存储在任何字节都是对齐的,所以分配到22(0x16)的单元中,只需一次寄存器读入;
对于成员stu.h,是一个2字节的变量,2字节对齐即可,分配到24-25(0x18-0x19)单元中,只需一次寄存器读入;
则得到如下分配图:

到这里还没有结束,如果定义一个结构体数组 stuA[2],按变量分配的原则,这2个结构体应该是在内存中连续存储的,分配应该如下图:

stuA[0]数据保证对齐了,但是stuA[1]的很多成员都不再对齐了,究其原因,是违反了字节对齐规则2:即stuA[1]结构体第一个数据成员的地址不是MIN(内存存取粒度n,该数据成员的自身长度)的倍数,stuA[1]结构体的开始边界不对齐。解决办法是:
字节对齐规则3:结构体长度一定是MIN(内存存取粒度n,结构体中数据成员最大长度)的整数倍。
如果stuA[0]的长度是MIN(内存存取粒度n,该数据成员的自身长度)的整数倍,那么stuA[1]结构体第一个数据成员的地址一定是MIN(内存存取粒度n,该数据成员的自身长度)的倍数,从而满足字节对齐规则2,stuA[1]的数据成员也就都对齐了,如图所示:

因此结构体变量分配到25字节单元中,25不是8的整数倍,因此取最近的整数32作为结构体变量的大小,从26字节开始,后面的字节单元全部被浪费掉。所有这些内存字节对齐工作都由编译器来完成。
指令#pragma pack(n)
#pragma pack(n)用来设置内存存取粒度为n,C编译器将按照n个字节对齐。
例子7
#include <iostream>
#include <stdio.h>
using namespace std;
#pragma pack(4) //设置4字节对齐
struct T
{
char c; //本身长度1字节
__int64 d; //本身长度8字节
int e; //本身长度4字节
short f; //本身长度2字节
char g; //本身长度1字节
short h; //本身长度2字节
}TT;
int main(){
//按照上面所说的方法推算 输出应是24个字节
cout<<"sizeof(TT)="<<sizeof(TT)<<endl;
system("pause");
}
#####例子8
#include <iostream>
#include <stdio.h>
using namespace std;
struct stu1{
char sex;
int length;
char name[10];
}my_stu1;
struct stu2{
int length;
char name[10];
char sex;
}my_stu2;
struct stu3{
short length;
char sex;
}my_stu3;
struct stu4{
int length;
double sex;
}my_stu4;
struct stu5{
char x1;
short x2;
float x3;
char x4;
}my_stu5;
int main(){
cout<<"sizeof(my_stu1)="<<sizeof(my_stu1)<<endl; //20
cout<<"sizeof(my_stu2)="<<sizeof(my_stu2)<<endl; //16
cout<<"sizeof(my_stu3)="<<sizeof(my_stu3)<<endl; //4
cout<<"sizeof(my_stu4)="<<sizeof(my_stu4)<<endl; //16
cout<<"sizeof(my_stu5)="<<sizeof(my_stu5)<<endl; //12
system("pause");
}
例子9
#include <iostream>
#include <stdio.h>
using namespace std;
#pragma pack(4)
struct stu1{
char sex;
int length;
char name[10];
}my_stu1;
struct stu2{
int length;
char name[10];
char sex;
}my_stu2;
struct stu3{
short length;
char sex;
}my_stu3;
struct stu4{
int length;
double sex;
}my_stu4;
struct stu5{
char x1;
short x2;
float x3;
char x4;
}my_stu5;
int main(){
cout<<"sizeof(my_stu1)="<<sizeof(my_stu1)<<endl; //20
cout<<"sizeof(my_stu2)="<<sizeof(my_stu2)<<endl; //16
cout<<"sizeof(my_stu3)="<<sizeof(my_stu3)<<endl; //4
cout<<"sizeof(my_stu4)="<<sizeof(my_stu4)<<endl; //12
cout<<"sizeof(my_stu5)="<<sizeof(my_stu5)<<endl; //12
system("pause");
}
例子10
typedef struct A
{
char c; //1个字节
int d; //4个字节,要与4字节对齐,所以分配至第4个字节处
short e; //2个字节, 上述两个成员过后,本身就是与2对齐的,所以之前无填充
}; //整个结构体,最长的成员为4个字节,需要总长度与4字节对齐,所以, sizeof(A)==12
typedef struct B
{
char c; //1个字节
__int64 d; //8个字节,位置要与8字节对齐,所以分配到第8个字节处
int e; //4个字节,成员d结束于15字节,紧跟的16字节对齐于4字节,所以分配到16-19
short f; //2个字节,成员e结束于19字节,紧跟的20字节对齐于2字节,所以分配到20-21
A g; //结构体长为12字节,最长成员为4字节,需按4字节对齐,所以前面跳过2个字节, 到24-35字节处
char h; //1个字节,分配到36字节处
int i; //4个字节,要对齐4字节,跳过3字节,分配到40-43 字节
}; //整个结构体的最大分配成员为8字节,所以结构体后面加5字节填充,被到48字节。故:sizeof(B)==48;