系统调用是为了扩充机器功能、增强系统能力、方便用户使用而建立的。用户程序或其他系统程序通过系统调用就可以访问系统资源,调用操作系统功能,而不必了解操作系统内部结构和硬件细节,它是用户程序或其他系统程序获得操作系统服务的唯一途径。
操作系统提供的系统调用很多,从功能上大致可分成五类:
1)进程和作业管理:终止或异常终止进程、装入和执行进程、创建和撤销进程、获取和设置进程属性。
2)文件操作:建立文件、删除文件、打开文件、关闭文件、读写文件、获得和设置文件属性。
3)设备管理:申请设备、释放设备、设备I/O和重定向、获得和设置设备属性、逻辑上连接和释放设备。
4)内存管理:申请内存和释放内存。
5)信息维护:获取和设置曰期及时间、获得和设置系统数据。
6)网络通信:建立和断开通信连接、发送和接收消息、传送状态信息、联接和断开远程设备。
什么是系统调用?什么是库函数?二者有何区别?
所谓系统调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核中实现的,再通过一定的方式把系统调用给用户,一般都通过门(gate)陷入(trap)实现。系统调用是用户程序和内核交互的接口。
我们在长期编程中发现使用系统调用有个重大的缺点,那就程序的移植性,比如说:linux系统提供的系统调用的函数和windows就不一样,2者不单单是实现的方式不同,提供给用户的函数名,参数都不同,这个可以理解。因此一个实现好的程序,利用了linux的系统调用比如说wait4函数,那么他在windows上编译是通不过的。于是人们想了个办法,就是封装了windows和linux系统调用,给大家一个统一的函数(我习惯叫它接口),那么这样程序的移植性问题就解决了。
所以可以这么认为库函数是对系统调用的封装(不是所有的库函数都是),为的是解决一些公共的问题和提供统一的系统调用的接口,他和系统调用的优缺点就是:系统调用速度是明显要快于库函数(并不一定全部是,但绝大部分是),但系统调用缺乏移植性。库函数速度要慢,但解决了移植问题。这些在开发过程中要根据自己的实际情况来决定使用那一个。
Linux系统调用的实现过程
通常,在OS的核心中都设置了一组用于实现各种系统功能的子程序(内核函数),并将它们提供给用户调用。每当用户在程序中需要OS提供某种服务时,变可利用一条系统调用命令,去调用系统过程。通过中断进入系统子程序执行;
1. 执行用户程序(如:fork)
2. 根据glibc中的函数实现,取得系统调用号并执行int $0x80产生中断。
3. 进行地址空间的转换和堆栈的切换,执行SAVE_ALL。(进行内核模式)
4. 进行中断处理,根据系统调用表调用内核函数。
5. 执行内核函数。
6. 执行RESTORE_ALL并返回用户模式
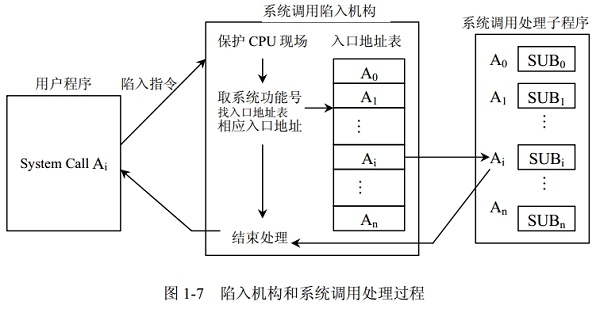
用户在程序中使用系统调用,给出系统调用名和函数后,即产生一条相应的陷入指令,通过陷入处理机制调用服务,引起处理机中断,然后保护处理机现场,取系统调用功能号并寻找子程序入口,通过入口地址表来调用系统子程序,然后返回用户程序继续执行。